برآورد هزینه توسعه DeepSeek نشاندهنده سرمایهگذاری عظیم و چند میلیون دلاری (یا حتی بیشتر) در منابع محاسباتی قدرتمند، جمعآوری و پردازش دادههای گسترده و بهکارگیری تیمهای متخصص هوش مصنوعی است. این ارقام سنگین، که شامل هزینههای زیرساخت، داده و نیروی انسانی متخصص میشود، بیانگر پیچیدگی و مقیاس عظیم پروژههای توسعه هوش مصنوعی مولد در سطح جهانی است و درک آن برای فعالان این حوزه ضروری میباشد.
برای اطلاع از جزئیات دقیقتر این هزینهها، عوامل موثر بر آن و تحلیل عمیقتر سرمایهگذاریهای لازم برای ساخت چنین مدلهای پیشرفتهای، مطالعه ادامه این مقاله اطلاعات جامعی را در اختیار شما قرار خواهد داد.
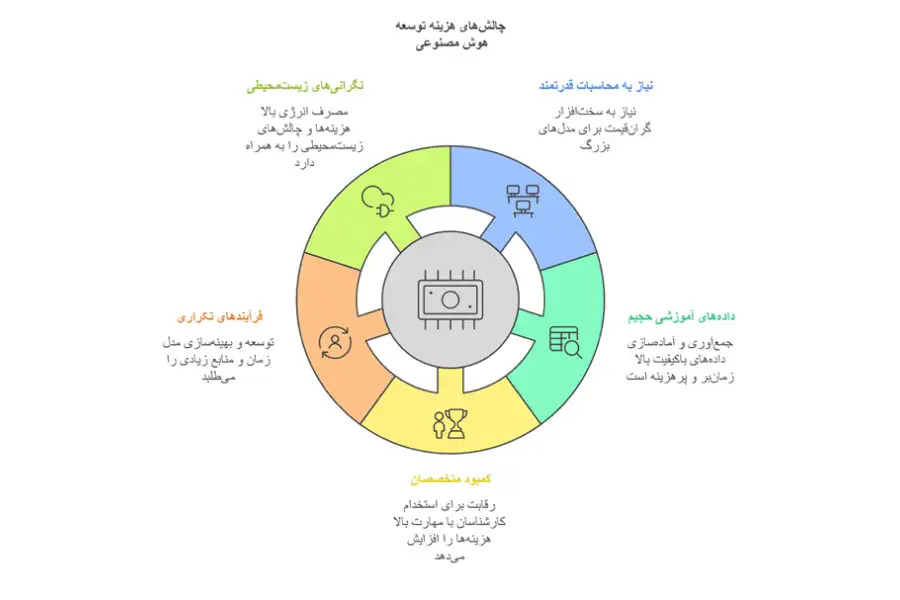
چرا هزینههای توسعه AI چالشبرانگیز است؟ نگاهی دقیقتر به عوامل اصلی

توسعه مدلهای هوش مصنوعی، بهخصوص مدلهای زبانی بزرگ که این روزها بسیار مورد توجه هستند، به دلایل مختلف هزینهبر است. درک این چالشها به ما کمک میکند تا ارزش هزینه توسعه DeepSeek را بهتر بفهمیم.
نیاز به قدرت محاسباتی بسیار زیاد
مدلهای هوش مصنوعی پیشرفته امروزی مانند ابزار چت جی پی تی، با میلیاردها یا حتی تریلیونها پارامتر (متغیرهای قابل تنظیم مدل)، به سختافزارهای محاسباتی بسیار قوی نیاز دارند. این سختافزارها معمولاً شامل خوشههای پردازندههای گرافیکی (GPU) گرانقیمت میشوند. هزینه خرید، راهاندازی و نگهداری این زیرساختها، بهویژه برای آموزش مدلهای بزرگ، بخش قابل توجهی از بودجه توسعه را به خود اختصاص میدهد. تصور کنید برای آموزش یک مدل زبانی بزرگ، به یک مزرعه سرور پر از GPU نیاز دارید که اجاره ماهانه آن میتواند به دهها هزار دلار برسد.
دادههای آموزشی حجیم و باکیفیت، یک چالش بزرگ
عملکرد یک مدل هوش مصنوعی بهطور مستقیم به دادههایی که با آن آموزش داده شده، بستگی دارد. برای اینکه مدل بهخوبی کار کند، نیاز به حجم زیادی از دادههای متنوع، دستهبندیشده و تمیز دارد. جمعآوری، آمادهسازی و برچسبگذاری این دادهها، هم زمانبر است و هم هزینه زیادی دارد. مثلا برای آموزش یک مدل تشخیص اشیا در تصاویر، ممکن است نیاز به میلیونها تصویر داشته باشید که هرکدام باید بهدقت برچسبگذاری شوند. این کار میتواند بسیار پرهزینه باشد.
هوش مصنوعی هوشا، یک دستیار هوشمند فارسی برای زندگی دیجیتال است؛ از خرید آنلاین و تولید محتوا گرفته تا تحلیل بازار و رشد بیزینس. این هوش مصنوعی با ابزارها و دستیارهای متنوع و بدون نیاز به دانش فنی به شما کمک میکند تا سریعتر تصمیم بگیرید، خلاقتر عمل کنید و حرفهایتر پیش بروید. در ویدیوی زیر کاربردهای آن را مرور کردهایم:
کمبود متخصصان و رقابت برای استخدام
حوزه هوش مصنوعی بهسرعت در حال پیشرفت و تقاضا برای متخصصان ماهر در این زمینه بسیار زیاد است. این کمبود متخصص، رقابت شدیدی را برای جذب و استخدام آنها ایجاد کرده است. شرکتها مجبورند برای جذب نیروهای متخصص با مهارتهای بالا، حقوق و مزایای خوبی بدهند که این موضوع باعث افزایش هزینههای نیروی انسانی در پروژههای هوش مصنوعی میشود.
فرایند توسعه تکراری و آزمون و خطا
توسعه و بهینهسازی مدلهای هوش مصنوعی یک فرایند پیچیده و مرحلهبهمرحله است. برای بهبود عملکرد مدل، باید آزمایشهای زیادی انجام شود، نتایج ارزیابی شوند، پارامترهای مختلف تنظیم و این مراحل دوباره تکرار شوند. این فرایند آزمون و خطا، نه تنها زمانبر است، بلکه بهدلیل نیاز به استفاده مکرر از منابع محاسباتی، هزینههای زیادی را هم به پروژه تحمیل میکند.
مصرف انرژی بالا و نگرانیهای محیط زیستی
آموزش مدلهای بزرگ هوش مصنوعی، بهخصوص با استفاده از خوشههای GPU، انرژی زیادی مصرف میکند. این مصرف بالای انرژی، هم هزینههای عملیاتی را افزایش میدهد و هم نگرانیهای مربوط به محیط زیست را به دنبال دارد. در دنیای امروز که توجه به مسائل زیستمحیطی مهم است، این جنبه از هزینههای توسعه هوش مصنوعی نیز اهمیت پیدا میکند.
این چالشها باعث شدهاند که هزینه توسعه هوش مصنوعی DeepSeek همه را شگقتزده کند. زیرا توانسته است هزینههای توسعه هوش مصنوعی را به میزان قابل توجهی کاهش دهد و امکان دسترسی به این فناوری قدرتمند را برای سازمانها و توسعهدهندگان بیشتری فراهم کند.
DeepSeek چگونه هزینههای توسعه مدلهای هوش مصنوعی را کاهش داده است؟
DeepSeek با استفاده از فناوریهای پیشرفته و استراتژیهای هوشمندانه، نقش مهمی در کاهش هزینه توسعه هوش مصنوعی ایفا میکند. این مدل با ترکیب نوآوریهای فنی و روشهای بهینهسازی، به طور مستقیم چالشهای مالی توسعه AI را هدف قرار میدهد:
معماری MoE (Mixture of Experts)
DeepSeek بهجای استفاده از یک مدل بزرگ و پیچیده که همه کارها را با هم انجام میدهد، از معماری MoE استفاده میکند. در این معماری، مدل به چندین متخصص کوچکتر تقسیم میشود که هرکدام در یک زمینه خاص تخصص دارند. فقط متخصصانی که برای انجام یک کار مشخص لازم هستند، فعال میشوند. این روش باعث میشود که نیاز به قدرت محاسباتی کم شود و در نتیجه هزینه توسعه DeepSeek و همچنین هزینه استفاده از آن کاهش یابد.
فرض کنید برای پاسخ به سوالات مختلف، بهجای یک متخصص همهفنحریف که برای هر سوال باید همه دانش خود را به کار بگیرد، از مجموعهای از متخصصان استفاده کنید که هرکدام فقط در زمینه تخصصی خود به سوالات پاسخ میدهند. این کار هم سریعتر انجام و هم منابع کمتری مصرف میشود.
تکنیک MLA (Multi-head Latent Attention)
تکنیک MLA یکی دیگر از نوآوریها برای کاهش هزینه توسعه هوش مصنوعی با دیپ سیک است. MLA با بهینهسازی نحوه توجه مدل به اطلاعات، حجم حافظه مورد نیاز برای پردازش اطلاعات را کم میکند و سرعت پردازش را بالا میبرد. این بهینهسازی نهتنها باعث میشود که مدل سریعتر پاسخ دهد، بلکه هزینههای مربوط به حافظه و زیرساختهای محاسباتی را هم کاهش میدهد.
تصور کنید که برای پیدا کردن یک کتاب در یک کتابخانه بزرگ، بهجای اینکه تمام قفسهها را بگردید، از یک فهرست راهنما استفاده کنید که شما را مستقیماً به قفسه مورد نظر هدایت کند. MLA شبیه به این فهرست راهنما عمل میکند و باعث میشود مدل سریعتر و با حافظه کمتری اطلاعات را پردازش کند و هزینه توسعه DeepSeek کاهش یابد.
هوش مصنوعی DeepSeek راهی نوین برای تولید متن، پاسخگویی هوشمند و پردازش زبان طبیعی با دقت بالا است. اگر میخواهید با قابلیتهای این مدل قدرتمند آشنا شوید و نحوه بهکارگیری آن را یاد بگیرید، مطالعه مقاله استفاده از هوش مصنوعی دیپ سیک را از دست ندهید!

آموزش با دقت مختلط FP8
DeepSeek از فرمت FP8 (Floating Point 8-bit) برای آموزش مدلهای خود استفاده میکند. فرمت FP8 نسبت به فرمتهای رایج FP16 و FP32، دقت محاسباتی کمتری دارد، اما سریعتر است و حافظه کمتری مصرف میکند. استفاده از FP8 باعث میشود که آموزش مدل با سرعت بیشتری انجام شود و هزینههای محاسباتی توسعه DeepSeek کاهش یابد. DeepSeek با استفاده از تکنیکهای پیشرفته، اطمینان حاصل میکند که این کاهش دقت، تاثیر منفی بر عملکرد مدل نداشته باشد.
فرض کنید برای محاسبات روزمره، نیازی به استفاده از ماشینحسابهای خیلی دقیق با تعداد رقم اعشار زیاد ندارید. استفاده از ماشین حسابهای معمولی که دقت کمتری دارند، سرعت محاسبات را بیشتر و منابع کمتری مصرف میکند. FP8 شبیه به این ایده عمل میکند و با کاهش دقت محاسبات در حد لازم، هزینه توسعه DeepSeek را کاهش میدهد.
الگوریتم DualPipe
آموزش مدلهای بزرگ هوش مصنوعی معمولاً بهصورت توزیعشده بر روی خوشههای GPU انجام میشود، یعنی کار بین چندین GPU تقسیم میشود. الگوریتم DualPipe DeepSeek با بهینهسازی نحوه ارتباط بین GPUها در آموزش توزیعشده، زمان بیکاری سیستم را کاهش میدهد و از هدر رفتن منابع جلوگیری میکند. این الگوریتم با همپوشانی محاسبات و ارتباطات، کارایی کلی سیستم را افزایش میدهد و هزینه توسعه DeepSeek و آموزش آن را کم میکند.
تصور کنید چند کارگر با هم یک کار ساختمانی را انجام میدهند. اگر هماهنگی بین کارگران خوب نباشد و بعضی از آنها منتظر بمانند تا کارگران دیگر کارشان را تمام کنند، زمان و هزینه پروژه افزایش پیدا میکند. DualPipe شبیه به یک مدیر پروژه عمل میکند که هماهنگی بین GPUها را بهینه میکند تا زمان و هزینه آموزش کاهش یابد.
هدف آموزش پیشبینی چند توکنی (MTP)
روشهای سنتی آموزش مدلهای زبانی معمولاً بر پیشبینی تکتوکنی (Single Token Prediction) تمرکز دارند، یعنی مدل در هر مرحله فقط یک کلمه یا بخشی از کلمه را پیشبینی میکند. DeepSeek از هدف آموزش پیشبینی چند توکنی (MTP) استفاده میکند. MTP به مدل اجازه میدهد تا در هر مرحله، چندین توکن را بهطور همزمان پیشبینی کند. این تکنیک باعث میشود مدل اطلاعات بیشتری را از دادههای آموزشی با تعداد کمتر داده دریافت کند و هزینه توسعه هوش مصنوعی با دیپ سیک از طریق کاهش نیاز به دادههای آموزشی بیشتر، کاهش یابد.
فرض کنید به یک دانشآموز یک متن کوتاه برای یادگیری میدهید. اگر دانشآموز بتواند بهجای خواندن کلمهبهکلمه، جملات یا عبارات را بهطور همزمان درک کند، سریعتر یاد میگیرد و به منابع کمتری نیاز دارد. MTP شبیه به این روش یادگیری عمل میکند و باعث میشود مدل با دادههای کمتری بهخوبی آموزش ببیند.
با استفاده از این نوآوریهای فنی و استراتژیهای هوشمندانه، DeepSeek نهتنها از نظر عملکرد به مدلهای پیشرفته دیگر نزدیک شده است، بلکه هزینه توسعه DeepSeek بسیار پایینتر نسبت به مدلهای مشابه است. این هوش مصنوعی نشان داده است که کاهش هزینه توسعه هوش مصنوعی به معنای کاهش کیفیت نیست، بلکه با نوآوری و بهینهسازی میتوان به عملکردی رقابتی و حتی بهتر با هزینههای کمتر دست یافت.

مقایسه هزینههای DeepSeek با GPT-4 و سایر مدلها
برای اینکه مزیتهای اقتصادی هزینه توسعه DeepSeek را بهتر درک کنیم، مقایسه هزینههای پردازش 1 میلیون توکن (واحد شمارش متن) در مدلهای مختلف بسیار مفید است. این مقایسه به ما نشان میدهد که برای پردازش حجم مشخصی از متن، استفاده از DeepSeek چه میزان صرفهجویی در هزینه به همراه دارد.
حال که دانستید انواع مدلهای زبانی هوش مصنوعی چیست، در جدول زیر، هزینههای مربوط به پردازش 1 میلیون توکن ورودی و خروجی در مدلهای مختلف هوش مصنوعی آورده شده است. این هزینهها براساس آخرین اطلاعات موجود و به دلار آمریکا محاسبه شدهاند:
| مدل | توکنهای ورودی (به ازای 1 میلیون توکن) | توکنهای خروجی (به ازای 1 میلیون توکن) | هزینه کل (به ازای 1 میلیون توکن) |
| DeepSeek-Chat (V3) | 0.07 تا 0.27 دلار | 1.10 دلار | 1.17 تا 1.37 دلار |
| DeepSeek-R1 | 0.14 تا 0.55 دلار | 2.19 دلار | 2.33 تا 2.74 دلار |
| OpenAI GPT-4o | 5.00 دلار | 15.00 دلار | 20.00 دلار |
| OpenAI GPT-4 Turbo | 10.00 دلار | 30.00 دلار | 40.00 دلار |
| OpenAI GPT-3.5 Turbo | 0.50 دلار | 1.50 دلار | 2.00 دلار |
همانطور که در جدول مشاهده میکنید، DeepSeek-Chat (V3) بهطور قابل توجهی مقرونبهصرفهتر از سایر مدلهای پیشرفته، به ویژه مدلهای OpenAI GPT-4 است. بهعنوان مثال، هزینه پردازش 1 میلیون توکن با DeepSeek-Chat (V3) حدود 1.17 تا 1.37 دلار است، در حالیکه همین میزان پردازش با GPT-4 Turbo حدود 40 دلار هزینه دارد. این اختلاف چشمگیر در هزینهها نشان میدهد که DeepSeek چگونه با نوآوریهای خود توانسته است هزینه توسعه و استفاده از هوش مصنوعی را به شکل قابل ملاحظهای کاهش دهد.
این کاهش هزینه توسعه DeepSeek، بهویژه برای کسبوکارها و سازمانهایی که حجم بالایی از پردازش متن دارند یا بهدنبال استفاده گسترده از هوش مصنوعی در محصولات و خدمات خود هستند، بسیار حائز اهمیت است. DeepSeek با ارائه یک مدل باکیفیت و در عین حال مقرونبهصرفه، امکان دسترسی به فناوریهای پیشرفته هوش مصنوعی را برای طیف وسیعتری از کاربران فراهم و به کاهش هزینه توسعه هوش مصنوعی با دیپ سیک کمک میکند.
استراتژیهای DeepSeek برای بهینهسازی هزینهها
DeepSeek علاوه بر نوآوریهای فنی، از استراتژیهای کلی و مدیریت هوشمندانه منابع برای بهینهسازی هزینههای توسعه هوش مصنوعی استفاده میکند:
- رویکرد متنباز و جامعهمحور: DeepSeek مدلهای خود را به صورت متنباز ارائه میدهد، یعنی کد منبع آنها برای عموم قابل دسترس است. این رویکرد باعث میشود که از مشارکت جامعه جهانی توسعهدهندگان بهرهمند شود. این مشارکت نه تنها هزینه توسعه DeepSeek را کاهش میدهد، بلکه باعث تسریع نوآوری و بهبود کیفیت مدلها از طریق بازخورد و همکاری متخصصان مختلف میشود.
- تمرکز بر کارایی در تمام مراحل: DeepSeek از مراحل اولیه طراحی معماری مدل تا انتخاب روشهای آموزشی و بهینهسازی کد، همهچیز را با هدف کاهش هزینهها و افزایش کارایی انجام میدهد. این رویکرد جامع باعث میشود که هزینههای محاسباتی، عملیاتی و زمان توسعه به حداقل برسد و مدلهای کارآمد و مقرونبهصرفه تولید شوند.
- بهرهگیری از سختافزار بهینه: DeepSeek با استفاده از سختافزارهای بهینه و متناسب با نیازهای خود، تلاش میکند هزینههای زیرساختی را کاهش دهد. انتخاب GPUهای مناسب، شبکههای پرسرعت و الگوریتمهای بهینهسازی مصرف منابع، به کاهش هزینه توسعه DeepSeek کمک میکند.
- مسئولیتپذیری زیستمحیطی: DeepSeek با توجه به نگرانیهای مربوط به مصرف انرژی بالای آموزش مدلهای بزرگ، تلاش میکند با کاهش مصرف انرژی و استفاده از روشهای پایدار، به حفظ محیط زیست کمک کند و در عین حال هزینههای انرژی را نیز کاهش دهد.
- تأکید بر کیفیت دادههای آموزشی: DeepSeek با تمرکز بر انتخاب دادههای آموزشی باکیفیت و مرتبط، تلاش میکند نیاز به حجم زیادی از دادههای بیکیفیت را کاهش دهد. این استراتژی باعث افزایش کارایی فرایند آموزش و کاهش هزینههای مربوط به دادهها میشود، زیرا جمعآوری و پردازش دادههای کمتر و باکیفیتتر، هزینه کمتری دارد.
با اتخاذ این استراتژیهای کلی، DeepSeek به یک نمونه موفق در کاهش هزینه توسعه هوش مصنوعی با دیپ سیک تبدیل شده است و راهکاری جامع برای کاهش هزینههای توسعه و دسترسی آسانتر به هوش مصنوعی ارائه میدهد.
سخن پایانی
در مجموع، DeepSeek به عنوان یک نوآوری مهم در حوزه هوش مصنوعی، با استفاده از راهکارهای فنی پیشرفته و استراتژیهای مدیریت منابع، توانسته است هزینههای توسعه مدلهای AI را به میزان قابل توجهی کاهش دهد. این هوش مصنوعی با ارائه یک مدل مقرونبهصرفه و باکیفیت، زمینه را برای تحول در صنایع مختلف فراهم کرده است. کاهش هزینه توسعه DeepSeek بهوسیله این نوآوری، به کسبوکارها کمک میکند تا با سرمایهگذاری کمتر، از فناوریهای پیشرفته بهرهمند شوند و در بازار رقابتی موفقتر عمل کنند.
معماری MoE در DeepSeek چگونه مصرف منابع را بهینه میکند؟
معماری MoE با تقسیم مدل به بخشهای تخصصی کوچکتر، فقط بخشهای ضروری را در هر لحظه فعال میکند. این کار باعث میشود که مصرف منابع محاسباتی و حافظه به طور قابل توجهی کم شود و در نتیجه زمان آموزش و هزینهها کاهش یابند.
چه تکنیکهایی در DeepSeek برای حفظ دقت FP8 Mixed Precision به کار گرفته میشود؟
DeepSeek از تکنیکهای پیشرفته کوانتیزاسیون و تنظیم دقیق پارامترها استفاده میکند تا با وجود استفاده از فرمت FP8 که دقت کمتری دارد، همچنان دقت مدل را در سطح قابل قبولی حفظ کند. DeepSeek به طور مشابه، با استفاده از تکنیکهای پیشرفته، دقت محاسبات را در قسمتهای مختلف مدل تنظیم میکند تا هم سرعت آموزش بالا باشد و هم دقت مدل حفظ شود.
الگوریتمهای بهینهسازی ارتباطی در DeepSeek چگونه عملکرد توزیعشده را ارتقا میدهند؟
الگوریتمهایی مانند DualPipe با همپوشانی محاسبات و ارتباطات میان GPUها، زمان بیکاری سیستم را کاهش داده و از ایجاد گلوگاههای ارتباطی جلوگیری میکنند. الگوریتم DualPipe با همپوشانی محاسبات و ارتباطات بین GPUها، کارایی سیستم را افزایش میدهد و زمان آموزش را کم میکند.
 تبدیل عکس به انیمه با ChatGPT | متن آماده + آموزش کامل
تبدیل عکس به انیمه با ChatGPT | متن آماده + آموزش کامل هوش مصنوعی پزشک: مشاوره رایگان، تفسیر آزمایش و بررسی علائم
هوش مصنوعی پزشک: مشاوره رایگان، تفسیر آزمایش و بررسی علائم هوش مصنوعی مترجم: ترجمه مقاله، عکس و فایل PDF
هوش مصنوعی مترجم: ترجمه مقاله، عکس و فایل PDF کسب درآمد دلاری با هوش مصنوعی (راهنمای کامل برای ایرانیان)
کسب درآمد دلاری با هوش مصنوعی (راهنمای کامل برای ایرانیان) مقایسه مربی بدنسازی انسانی با هوش مصنوعی؛ بررسی مزایا و معایب
مقایسه مربی بدنسازی انسانی با هوش مصنوعی؛ بررسی مزایا و معایب