یادگیری ماشین، زیرشاخهای کلیدی از هوش مصنوعی، به سیستمها توانایی یادگیری خودکار از دادهها و بهبود عملکرد بدون برنامهنویسی صریح را میبخشد. این فناوری با شناسایی الگوها و استخراج دانش از دادههای حجیم، امکان پیشبینی، طبقهبندی و تصمیمگیری هوشمندانه را در حوزههای مختلف فراهم میآورد. برای درک عمیقتر انواع الگوریتمها، کاربردهای عملی و پتانسیل تحولآفرین ماشین لرنینگ، به مطالعه ادامه این مطلب بپردازید.
ماشین لرنینگ چیست؟

هر روز حجم زیادی از اطلاعات در دنیای دیجیتال تولید میشود. کامپیوترها با روشی به نام ماشین لرنینگ میتوانند از این اطلاعات درس بگیرند و کارهای مفیدی انجام دهند. مثل وقتی که نرمافزار پزشکی با دیدن هزاران عکس اشعه ایکس، یاد میگیرد علائم بیماری را تشخیص دهد یا وقتی بانک با بررسی تراکنشهای مشتریان، متوجه خرید غیرعادی و کلاهبرداری میشود.
در واقع، یادگیری ماشین مثل یک دانشآموز است که با دیدن مثالهای بیشتر، تجربهاش زیاد میشود و بهتر میتواند تصمیم بگیرد. این فناوری امروزه به کمک انسانها آمده است تا در کارهای مختلف، تصمیمهای بهتر و سریعتری بگیرند و زندگی راحتتری داشته باشند.
تاریخچه مختصری از یادگیری ماشین
تاریخچه ماشین لرنینگ به دهه 1950 برمیگردد، زمانیکه اولین الگوریتمهای یادگیری مانند پرسپترون1 معرفی شدند. این الگوریتمها بهصورت ابتدایی طراحی شده بودند و توانایی شناسایی الگوهای ساده را داشتند. در دهه 1980، با پیشرفتهای تکنولوژیکی و افزایش قدرت محاسباتی، الگوریتمهای پیچیدهتری مانند شبکههای عصبی چندلایه توسعه یافتند.
این شبکهها بهخصوص در شناسایی الگوهای پیچیده و پردازش دادههای غیرخطی مؤثر بودند. در سالهای اخیر، ظهور دادههای بزرگ (Big Data) و افزایش دسترسی به منابع محاسباتی، یادگیری عمیق (Deep Learning) را به یکی از مهمترین حوزههای این فناوری تبدیل کرده است. این پیشرفتها باعث شدهاند که Machine learning در زمینههای مختلف مانند پزشکی، مالی، بازاریابی و فناوری اطلاعات به کار گرفته شود.
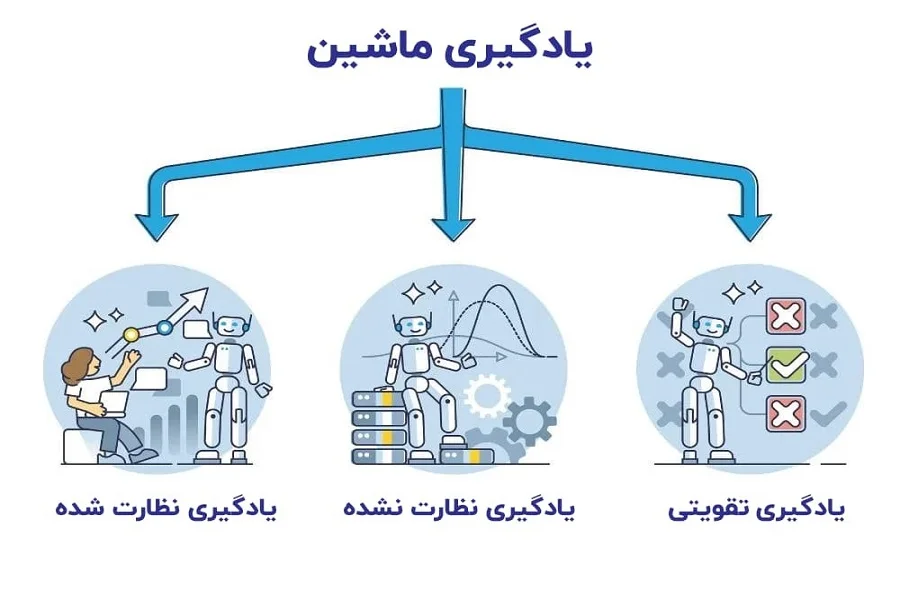
انواع یادگیری ماشین
یادگیری ماشین به سه دسته اصلی تقسیم میشود که در این بخش آنها را معرفی میکنیم.
یادگیری تحت نظارت (Supervised Learning)
در این نوع یادگیری، مدل با استفاده از دادههای برچسبگذاری شده آموزش میبیند. هدف این است که مدل بتواند ورودیهای جدید را براساس یادگیریهای قبلی پیشبینی کند. بهعنوان مثال، در تشخیص ایمیلهای اسپم، مدل با استفاده از ایمیلهای برچسبگذاریشده (اسپم یا غیر اسپم) آموزش میبیند. این نوع یادگیری در بسیاری از کاربردها مانند طبقهبندی تصاویر، پیشبینی قیمتها و تحلیل احساسات به کار میرود.
یادگیری بدون نظارت (Unsupervised Learning)
در این حالت، مدل بدون برچسب آموزش میبیند و به کشف الگوها و ساختارهای پنهان در دادهها میپردازد. این نوع یادگیری معمولاً برای تحلیل خوشهای (Clustering)2 و کاهش ابعاد (Dimensionality Reduction)3 استفاده میشود. بهعنوان مثال، در تحلیل دادههای مشتریان، مدل میتواند گروههایی از مشتریان با رفتارهای مشابه را شناسایی کند. این نوع یادگیری بهویژه در تجزیهوتحلیل دادههای بزرگ و کشف الگوهای جدید کاربرد دارد.
یادگیری تقویتی (Reinforcement Learning)
در این نوع ماشین لرنینگ، مدل از تعامل با محیط و دریافت بازخوردها یاد میگیرد. این روش در رباتیک و بازیها کاربرد دارد. در یادگیری تقویتی، مدل با دریافت پاداش یا تنبیه بهدنبال بهینهسازی رفتار خود است. این نوع یادگیری بهعنوان یک روش بسیار مؤثر در حل مسائل پیچیده و دینامیک شناخته میشود.
هوش مصنوعی هوشا یک دستیار هوشمند فارسیزبان است که با استفاده از فناوری پردازش زبان طبیعی، مکالمهای روان و کارآمد با کاربران برقرار میکند. این سامانه برای پاسخگویی به سوالات، کمک در یادگیری، تولید محتوا، انجام وظایف روزمره طراحی و بسیاری کاربردهای دیگر شده است.
الگوریتمهای یادگیری ماشین
چندین الگوریتم مختلف وجود دارند که در Machine learning مورد استفاده قرار میگیرند. برخی از مهمترین آنها عبارتاند از:
- درخت تصمیم (Decision Tree): یک مدل بصری که بهراحتی قابل تفسیر است و برای پیشبینی دستهها یا مقادیر عددی استفاده میشود. درخت تصمیم بهصورت سلسلهمراتبی عمل میکند و میتواند به راحتی تفسیر شود. این الگوریتم به ما این امکان را میدهد که تصمیمها را براساس ویژگیهای مختلف بگیریم.
- رگرسیون خطی (Linear Regression): برای پیشبینی مقادیر عددی براساس یک یا چند ویژگی استفاده میشود. این الگوریتم بهدنبال یافتن رابطهای خطی بین متغیرهاست و معمولاً در مسائل اقتصادی و مالی کاربرد دارد.
- شبکههای عصبی (Neural Networks): الگوریتمهایی که به تقلید از عملکرد مغز انسان طراحی شدهاند و برای مسائل پیچیدهای مانند شناسایی تصویر و پردازش زبان طبیعی کاربرد دارند. شبکههای عصبی شامل لایههای مختلفی هستند که هرکدام وظیفه خاصی دارند. این الگوریتمها معمولا در یادگیری عمیق مورد استفاده قرار میگیرند.
- ماشینهای بردار پشتیبان (Support Vector Machines): برای طبقهبندی دادهها و تشخیص الگو استفاده میشوند. این الگوریتمها بهدنبال یافتن بهترین مرز بین دستههای مختلف دادهها هستند و در مسائلی مانند شناسایی چهره و تشخیص دستخط کاربرد دارند.
- الگوریتمهای تقویتی (Reinforcement Algorithms): مانند Q-Learning و Deep Q-Networks، که برای یادگیری تقویتی استفاده میشوند و به مدلها اجازه میدهند تا از تجربیات گذشته خود برای بهبود عملکردشان استفاده کنند. این الگوریتمها معمولا در بازیهای رایانهای و رباتیک کاربرد دارند.
هوش مصنوعی با زبان برنامهنویسی پایتون به سادگی قابل پیادهسازی است و در زمینههایی مثل یادگیری ماشین، تحلیل داده و بینایی ماشین کاربرد دارد. اگر علاقهمند به یادگیری این موضوع هستید، حتماً مقاله کاربرد هوش مصنوعی در پایتون را بخوانید!
یادگیری عمیق چیست؟ از آغاز تا پیشرفتهای کنونی
نحوه کار و عملکرد ماشین لرنینگ
نحوه کار و عملکرد ماشین لرنینگ به چند مرحله اصلی تقسیم میشود که در ادامه به تفصیل بررسی میکنیم.
جمعآوری دادهها
جمعآوری دادهها اولین و مهمترین مرحله در فرایند ماشین لرنینگ است. در این مرحله، دادههای مرتبط با موضوع مورد نظر جمعآوری میشوند. این دادهها میتوانند شامل انواع مختلفی از اطلاعات مانند متن، تصویر، صدا و حتی دادههای عددی باشند. کیفیت و کمیت دادهها تأثیر زیادی بر عملکرد مدل یادگیری دارد. بهعنوان مثال، دادههای بزرگ و متنوع به مدل کمک میکنند تا الگوهای مختلف را شناسایی کند و در نتیجه پیشبینیهای دقیقتری انجام دهد. هرچه دادهها بیشتر و متنوعتر باشند، مدل توانایی بهتری در تعمیم و پیشبینی خواهد داشت.
پیشپردازش دادهها
پس از جمعآوری دادهها، مرحله پیشپردازش آغاز میشود. در این مرحله، دادهها باید تمیز و آمادهسازی شوند تا برای آموزش مدل مناسب باشند. این مرحله شامل حذف دادههای ناقص یا نادرست، نرمالسازی دادهها و تبدیل آنها به فرمتهای مناسب است. همچنین، ممکن است نیاز باشد که دادهها به دستههای مختلف تقسیم شوند تا مدل بتواند بهتر یاد بگیرد. پیشپردازش دادهها به ما این امکان را میدهد که دادههای با کیفیت بالا برای آموزش مدل داشته باشیم و از این طریق دقت پیشبینیهای مدل را افزایش دهیم.
آموزش مدل
آموزش مدل مرحلهای است که در آن مدل با استفاده از دادههای آموزشی، آموزش میبیند. در این مرحله، انتخاب الگوریتم مناسب و تنظیم پارامترهای آن اهمیت ویژهای دارد. مدل با استفاده از دادههای برچسبگذاری شده یاد میگیرد که چگونه دادههای جدید را پیشبینی کند. این مرحله بسیار حیاتی است، زیرا مدل باید توانایی یادگیری و تعمیم را به دست آورد. در واقع، آموزش مدل بهمعنای یافتن الگوهای نهفته در دادهها و یادگیری نحوه استفاده از این الگوها برای پیشبینیهای آینده است.
ارزیابی مدل
پس از آموزش مدل، نوبت به ارزیابی آن میرسد. در این مرحله از ماشین لرنینگ، مدل با استفاده از دادههای تست ارزیابی میشود تا عملکرد آن بررسی شود. معیارهای مختلفی مانند دقت، حساسیت و خاصیت برای ارزیابی به کار میروند. این مرحله به ما کمک میکند تا بفهمیم مدل چقدر خوب عمل میکند و آیا نیاز به بهبود دارد یا خیر. ارزیابی مدل به ما این امکان را میدهد که نقاط قوت و ضعف آن را شناسایی کنیم و در صورت نیاز، تغییرات لازم را اعمال کنیم. در این مرحله، ممکن است نیاز باشد که به تنظیم مجدد پارامترها یا حتی انتخاب الگوریتم جدید بپردازیم.
استفاده از مدل
پس از ارزیابی و اطمینان از عملکرد مناسب مدل، نوبت به استفاده از آن برای پیشبینیهای جدید است. در این مرحله، مدل میتواند بهطور خودکار به دادههای جدید پاسخ و پیشبینیهایی انجام دهد. این پیشبینیها میتوانند در تصمیمگیریهای تجاری، پزشکی و بسیاری از زمینههای دیگر مورد استفاده قرار گیرند. بهعنوان مثال، در صنعت پزشکی، مدلهای Machine learning میتوانند به پزشکان در تشخیص بیماریها کمک کنند یا در تجارت، میتوانند برای تحلیل رفتار مشتریان و پیشبینی فروش مفید باشند.
چت جی پی تی فارسی هوشا یک دستیار هوشمند مبتنی بر هوش مصنوعی است که امکان پاسخگویی سریع و دقیق به سوالات کاربران را در زمینههای مختلف، از جمله ماشین لرنینگ، فراهم میکند. این ابزار با تحلیل زبان طبیعی و دسترسی به منابع گسترده، یادگیری و تحقیق در موضوعات پیچیده را برای کاربران ساده و کارآمد میسازد. در ویدیوی زیر نحوه کار با این ابزار را آموزش دادهایم.
کاربردهای یادگیری ماشین در صنایع مختلف
یادگیری ماشین در صنایع مختلف کاربردهای فراوانی دارد، که در ادامه مهمترین آنها را معرفی میکنیم.
- پزشکی: تشخیص بیماریها و پیشبینی روند درمان. به عنوان مثال، الگوریتمهای ماشین لرنینگ میتوانند به تشخیص زودهنگام سرطان کمک کنند. این الگوریتمها با تحلیل تصاویر پزشکی یا دادههای ژنتیکی، احتمال ابتلا به بیماریها را پیشبینی میکنند. همچنین، این فناوری میتواند به پزشکان در انتخاب بهترین روش درمانی کمک کند.
- مالی: شناسایی تقلب و پیشبینی بازار. بانکها و مؤسسات مالی از این روش برای تحلیل رفتار مشتری و شناسایی الگوهای مشکوک بهره میبرند. این الگوریتمها میتوانند به شناسایی فعالیتهای غیرمعمول و جلوگیری از کلاهبرداری کمک کنند. بهعنوان مثال، الگوریتمهای Machine learning میتوانند تراکنشهای مشکوک را شناسایی کنند و بهسرعت به آنها پاسخ دهند.
- خودرو: سیستمهای رانندگی خودکار. شرکتهای خودروسازی از این فناوری برای توسعه خودروهای خودران استفاده میکنند. این خودروها با استفاده از دادههای حسگرها و دوربینها، محیط را تحلیل و تصمیمات لازم را اتخاذ میکنند. یادگیری ماشین میتواند به کاهش تصادفات و بهبود امنیت جادهها کمک کند.
- بازاریابی: تحلیل رفتار مشتری و شخصیسازی تبلیغات. با استفاده از این راهکار، شرکتها میتوانند تبلیغات خود را براساس علایق و رفتارهای مشتریان هدفگذاری کنند. این موضوع موجب افزایش نرخ تبدیل و بهبود تجربه مشتری میشود. مثلا، سیستمهای توصیهگر میتوانند به مشتریان پیشنهاد دهند که چه محصولاتی را خریداری کنند.
- تجارت الکترونیک: پیشنهاد محصولات براساس رفتار خرید مشتریان. سیستمهای توصیهگر میتوانند به مشتریان محصولاتی را پیشنهاد دهند که احتمال خرید آنها بیشتر است. این سیستمها با تحلیل دادههای مشتریان و رفتارهای خرید آنها، میتوانند تجربیات خرید را بهبود بخشند.
- کشاورزی: استفاده از Machine learning برای بهینهسازی فرایندهای کشاورزی، مانند پیشبینی تولید و تشخیص بیماریهای گیاهان. این تکنیکها میتوانند به کشاورزان کمک کنند تا تصمیمات بهتری در مورد کشت و برداشت محصولات بگیرند.
- خدمات عمومی: استفاده از ماشین لرنینگ برای بهبود خدمات عمومی، مانند پیشبینی تقاضا برای خدمات و بهینهسازی منابع. برای مثال، در خدمات حملونقل، این سیستم میتواند به پیشبینی ترافیک و بهبود زمانبندی خدمات کمک کند.
محدودیتهای یادگیری ماشین
Machine Learning مزایای زیادی دارد اما با محدودیتهایی نیز مواجه است که در این قسمت به آنها اشاره میکنیم.
- نیاز به دادههای بزرگ: بسیاری از الگوریتمها برای عملکرد بهتر به دادههای زیاد نیاز دارند. در صورتی که دادهها ناکافی یا ناکامل باشند، نتایج ممکن است نادرست باشند. این موضوع میتواند به عدم دقت در پیشبینیها منجر شود.
- عدم شفافیت: برخی مدلها بهعنوان «جعبه سیاه» عمل میکنند و تفسیر نتایج آنها دشوار است. این مسئله میتواند در حوزههایی مانند پزشکی و حقوقی مشکلساز باشد، زیرا نیاز به توضیحات دقیق و قابل فهم دارد. بههمین دلیل، توسعه مدلهای قابل تفسیر یکی از چالشهای مهم در ماشین لرنینگ است.
- تعصب دادهها: اگر دادهها متعصب باشند، نتایج نیز متعصب خواهند بود. این موضوع میتواند به تبعیض و نابرابری در تصمیمگیریها منجر شود. برای مثال، اگر دادههای آموزشی شامل نژاد یا جنسیت خاصی باشند، مدل ممکن است به نفع آن گروه عمل کند و به دیگران آسیب برساند.
- هزینههای بالای محاسباتی: برخی از الگوریتمهای این سیستم، بهویژه الگوریتمهای یادگیری عمیق، نیاز به محاسبات سنگینی دارند که میتواند هزینههای بالایی را به همراه داشته باشد. این موضوع میتواند برای شرکتهای کوچک و متوسط یک مانع باشد.
- خطرات امنیتی: Machine learning میتواند بهعنوان ابزاری برای حملات سایبری مورد استفاده قرار گیرد. مثلا، الگوریتمهای این فناوری میتوانند برای شناسایی نقاط ضعف در سیستمهای امنیتی استفاده شوند.
- نیاز به تخصص: استفاده مؤثر از این سیستم نیاز به دانش و تخصص دارد. توسعه و پیادهسازی مدلهای ماشین لرنینگ نیاز به مهارتهای فنی و علمی دارد که ممکن است برای برخی از سازمانها دشوار باشد.
سخن پایانی
با توجه به پیشرفتهای روزافزون در زمینه ماشین لرنینگ و هوش مصنوعی، انتظار میرود که این تکنیکها در آینده نزدیک نقشهای بیشتری در زندگی روزمره ما ایفا کنند. از بهبود خدمات بهداشتی و درمانی تا افزایش کارایی در صنایع مختلف، این فناوری میتواند به ما در دستیابی به اهداف بزرگتر کمک کند. همچنین، با توجه به چالشهایی که در این حوزه وجود دارد، نیاز به تحقیق و توسعه بیشتر در این زمینه احساس میشود.
یادگیری ماشین چه تفاوتی با هوش مصنوعی دارد؟
این فناوری زیرمجموعهای از هوش مصنوعی است که به سیستمها این امکان را میدهد که از دادهها یاد بگیرند. هوش مصنوعی شامل تمامی تکنیکها و روشهایی است که به ماشینها اجازه میدهد تا وظایف را بهصورت هوشمندانه انجام دهند.
آیا ماشین لرنینگ برای همه صنایع مناسب است؟
بله، این فناوری میتواند در بسیاری از صنایع کاربرد داشته باشد، اما نیاز به دادههای مناسب و زیرساختهای لازم دارد.
چطور میتوانم شروع به Machine learning کنم؟
میتوانید از دورههای آنلاین، کتابها و منابع آموزشی مختلف استفاده کنید. همچنین، با انجام پروژههای کوچک و تمرین بر روی دادههای واقعی، میتوانید تجربه عملی کسب کنید.
چه چالشهایی در پیادهسازی ماشین لرنینگ وجود دارد؟
چالشهای متعددی در پیادهسازی این فناوری وجود دارد، از جمله نیاز به دادههای با کیفیت، هزینههای بالای محاسباتی، عدم شفافیت مدلها و نیاز به تخصص فنی.
- پرسپترون (Perceptron): پرسپترون یک الگوریتم ساده و بنیادی در یادگیری ماشین است که برای دستهبندی دادهها به کار میرود. این الگوریتم با استفاده از وزنها و تابع فعالسازی، تعیین میکند که یک ورودی به کدام دسته تعلق دارد. پرسپترون به عنوان یکی از نخستین مدلهای شبکههای عصبی شناخته میشود. ↩︎
- تحلیل خوشهای (Clustering): تحلیل خوشهای یک روش در علم داده است که به ما کمک میکند تا دادهها را به گروههای مشابه تقسیم کنیم. تصور کنید که شما یک دسته از میوهها دارید. با استفاده از تحلیل خوشهای، میتوانید میوهها را براساس ویژگیهایی مثل رنگ، اندازه یا طعم به گروههای مختلف تقسیم کنید. ↩︎
- کاهش ابعاد (Dimensionality Reduction): کاهش ابعاد یک تکنیک در علم داده است که به ما کمک میکند تا دادههای پیچیده و بزرگ را سادهتر کنیم. تصور کنید که شما یک تصویر با میلیونها پیکسل دارید. اگر بخواهید ویژگیهای مهم این تصویر را استخراج کنید، میتوانید با کاهش ابعاد، اطلاعات اضافی را حذف کرده و فقط ویژگیهای کلیدی را نگه دارید. ↩︎
 دانلود چت جی پی تی برای ایفون (آموزش نصب نسخه اصلی و فارسی)
دانلود چت جی پی تی برای ایفون (آموزش نصب نسخه اصلی و فارسی) هوش مصنوعی نانو بنانا Nano Banana: آموزش + نمونه تصاویر
هوش مصنوعی نانو بنانا Nano Banana: آموزش + نمونه تصاویر ربات تغییر چهره تلگرام با هوش مصنوعی: تغییر سن، جنسیت، استایل و…
ربات تغییر چهره تلگرام با هوش مصنوعی: تغییر سن، جنسیت، استایل و… هوش مصنوعی معلم هوشا؛ تدریس خصوصی در خانه + آموزش کار
هوش مصنوعی معلم هوشا؛ تدریس خصوصی در خانه + آموزش کار هوش مصنوعی بدنسازی؛ مربی باشگاه رایگان برای گرفتن برنامه تمرینی و غذایی
هوش مصنوعی بدنسازی؛ مربی باشگاه رایگان برای گرفتن برنامه تمرینی و غذایی